
Tracking the front page of the New York Times
Part 2 of my New York Times investigation, where I take a close look at what kinds of articles make it to the front page.
In my last post I investigated how the New York Times A/B tests their headlines and found that A/B-tested headlines tend to get more dramatic over time. In this post I take a closer look at the front page: how does the New York Times populate its most precious real estate?
What’s a front page, old-timer?
Look I know it sounds crazy but they used to print the NYT on trees. A small child would bike past your house every morning and literally throw this tree-bundle at your front door and you’d flip through it over breakfast.
But it’s 2021 so I’m talking about the digital front page: everything that shows up when you first load www.nytimes.com. It looks like this:

If you scroll to the bottom of this page you might notice that more stories are loaded as you scroll. I’m not including these, because that content (usually under the heading “Other Stories”) is clearly Page 2 material.
Methodology
In a similar fashion to my A/B testing methodology, I wrote a web scraper that
Scrapes the front page of the New York Times every five minutes
Pulls out all articles
Associates them with canonical data from the NYT API
The end result is a time series of article data, answering the question: What articles were on the front page at time X?
Article turnover
The first question I had was: How often does the front page change?
If you’re old enough to remember tree-based newspapers, you might expect that articles stay on the front page for about a day. And you’d be sorta right. The vast majority of front-page articles stay on the front page for less than 24 hours, with the median article lasting about 9.5 hours.
But—get this—10% of front-page articles stay there for less than an hour:

In a post-paper world this makes sense. The NYT front page is precious real estate—if an article is underperforming they should quickly replace it with something that attracts more eyeballs. But it also means that we (readers) are missing out on the 10% of articles that weren’t engaging enough to survive.
So what articles do survive? In other words, what articles spend the most time on the front page?
The most promoted articles
The chart above is truncated at 48 hours—it omits a small percentage of articles that stay on the front page for several days. See, for example, this hard-hitting piece of reporting on scrambled eggs, which sat on the front page for six days:

In fact, most of the long-tenured articles I looked at were brazen puff pieces. Some even crossed the line into “this smells like an ad” territory. For example, it’s hard to look at this article as anything other than an ad for Norwegian Wool:
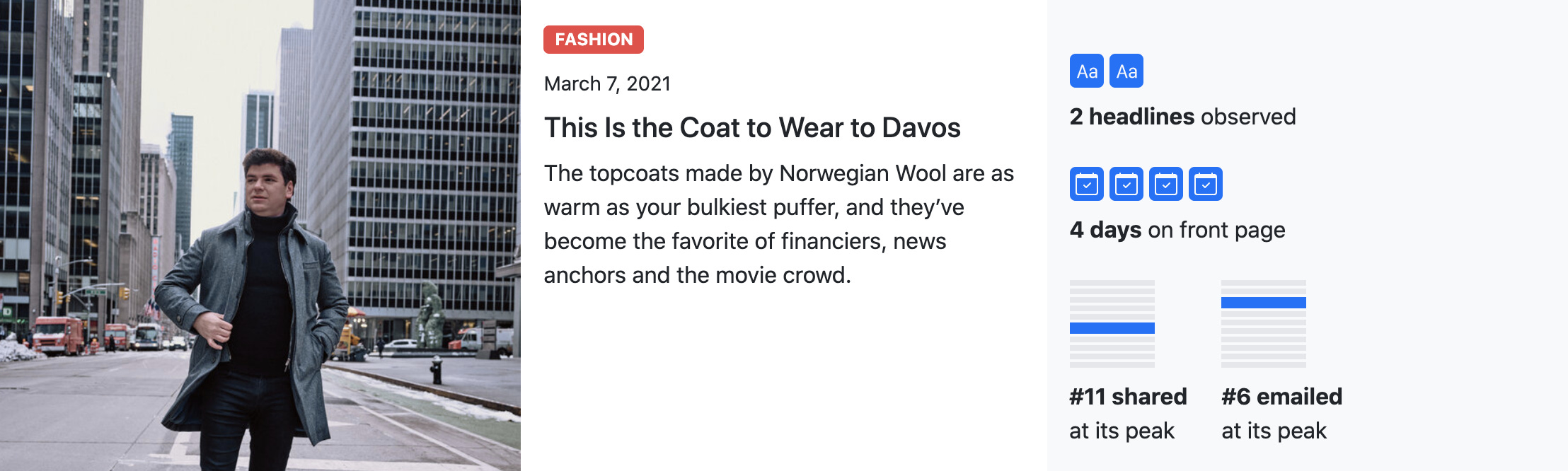
And it was on the front page for four days! Let’s not forget: a military junta is shooting protestors in Myanmar; 30,000 U.S. organizations have been hacked by the Chinese; there are serious wars happening in Afghanistan, Ethiopia, and Yemen—but the New York Times is saving their front-page real estate for the real news: a jacket that will make your shoulders pop at a conference in the Alps.
Taking a closer look at fluff
Maybe I’m being unfair—maybe “real news” changes quickly, and therefore has high turnover, even if overall the front page is mostly “real news.”
Here’s a better methodology: add up all the front-page hours for all articles and then see how these hours are split between “real news” and “fluff.”
Unfortunately there’s no obvious “fluff” field in the NYT API, so I had to get a bit creative.
Front page time, by tag
I knew that the NYT assigned tags to all its articles in an effort to organize them by topic. Since I’m trying to figure out which articles are “fluff,” I figured that these tags might provide a clue.
So I started by divvying up front-page time by tag:

The chart above (and the rest of the charts to follow) show the distribution of front-page hours, answering the question, “How much total front-page time is allotted to articles of type X?”
Anyway, this chart paints a fluff-less picture of the NYT front page. The top five tags are either about
US politics, or
COVID
And like, yeah, those are pretty serious topics in 2021.
But while these tags sound serious, it’s pretty easy to find fluffy articles with serious tags. The “Coronavirus (2019-nCoV)” tag certainly includes serious news, but it also applies to this wedding idea listicle, a review of wellness apps, and this weird admonition to have your kids do more chores.
So looking at tags is interesting but it doesn’t map cleanly to the fluff/news categories that I’m really after.
Front page time, by section
I know from TV that old-timey newspapers used to be organized into sections—each one physically separated from the rest—so that you and the other ad executives could trade them back and forth on the train while drinking scotch for breakfast.
These days newspaper sections are a bit more subtle (you can find them in the URL), but for our purposes sections have one great quality: each article can only have one. This means that an article’s section is a pretty good description of what the article is about (whereas an article can have an unlimited number of tags).
So once again I took a look at total front page time, this time by section:

Did you guess that the opinion section was the most-promoted section of the NYT? I was a bit surprised—I think of the front page as being full of breaking news—but the rest of these rankings make sense to me.
Sadly, I’m still running into the same problem as before: these sections don’t map very cleanly to my fluff/news categories. So while the serious-sounding “U.S.” section certainly contains lots of real news, it also has articles about poignant college-admission essays, bowling drones, and snowplows with punny names.
Ugh—back to the drawing board.
Catching a break
At this point I’m getting desperate. I Google “machine learning fluff articles” and “GPT-3 for puff pieces” to no avail. I start thinking about how long it would take me to go through the ~3,500 articles in my database and manually sort them into fluff/news categories.
But then I get lucky. I am, uh, casually browsing the New York Times’ undocumented GraphQL API (we all have our COVID hobbies) and come across a field called “tone” with these possible values:

This looked promising! It’s not something that the NYT displays on its website, but clearly “tone” is important enough for them to store in their article database. So I added this new field to my own database an discovered that roughly 55% of articles were NEWS, 35% were FEATURE and 10% were OPINION:

INFORMAL tone never shows up).What do these “tones” mean? NEWS seems pretty straightforward, as does OPINION, and NO_TONE_SET is rare enough to ignore. But what kind of tone is FEATURE? I took a random sample of FEATURE-toned headlines to find out:

FEATURE-toned headlinesBingo! I couldn’t have made up fluffier headlines. Clearly “feature” is some sort of industry term for fluff, and the New York Times already tracks it!
I did a little digging into what “feature” means and it turns out I’m a complete philistine: “feature” is an extremely well-known and widely-used category in the news biz—as Wikipedia tells me:
Unlike straight news, the feature story serves the purpose of entertaining the readers, in addition to informing them. Although truthful and based on good facts, they are less objective than straight news. Unlike straight news, the subject of a feature story is usually not time sensitive. It generally features good news. [Emphasis mine.]
And here I thought I had discovered fluff!
Front page time, by tone
Okay now that I’ve added tone to my database I can finally answer the question: How much of the NYT front page is fluff?
So here it is, the big reveal:

Answer: about 31.1% of the front page is fluff.
Or, put another way: less than half of the front page is news.
What about editorials?
The opinion section defies my news/fluff ontology—on the one hand editorials have been a central part of newspapers since forever, and they exert a powerful influence over public discourse. At their best, editorials help us understand the unceasing torrent of news and frame it within a broader context—so calling them “fluff” seems uncharitable.
But I’m still not convinced that editorials are news, either. There’s certainly no news happening when David Brooks holds forth on topics like How to love America, The case for Mike Bloomberg, or Nine non-obvious ways to have deeper conversations. These are more like sermons, where the point is moral or cultural transmission, not news.
Conclusion
We won’t solve the “are editorials news?” debate here, but it raises a more interesting question: What are we doing when we read the news?
I think some people view “reading the news” as an educational activity—reading the news means being informed, it means being a good citizen, it means being educated. In this view, scrolling through the NYT is good, while scrolling through Instagram is bad.
But I don’t think it’s that simple. The above analysis shows that less than half of what you read when scrolling through the NYT is news. The other half is
Other people’s opinions about that news
Stuff about scrambled eggs, trendy wool coats, Peloton, etc.
If you like reading the non-news stuff, that’s fine! But I often feel like there’s a bait-and-switch happening when I read the NYT. It’s too easy for me to slip from “I’m opening the NYT to stay updated on breaking news” to “I’ve been reading about holiday hams for half an hour.”
And this is probably by design! The NYT would prefer that you not shut your laptop when you’ve finished scanning today’s 10-15 news headlines—so they supplement it with white-collar clickbait like Shopping for Daybeds.
So recently I’ve been trying to read just news. I even created this page that only displays the NEWS articles from the NYT front page so that I can more easily ignore the other stuff.

NEWS-only version of the NYT front page.It’s a little less fun than the full NYT—but you won't waste time reading articles like When One Fridge Is Not Enough.
Next time
This post was all about what types of articles the NYT promotes—but another interesting question is: what types of articles do people read?
So next time I’ll be diving into article engagement: which articles are most likely to be clicked, emailed, or shared on social media? If you aren’t already a subscriber, smash the button below to stay tuned.